1. 위상 정렬
: 스킬트리도 그 중 하나지.
[1] 알고리즘 위상정렬
: 순서를 정해보자
ⓐ : 정의
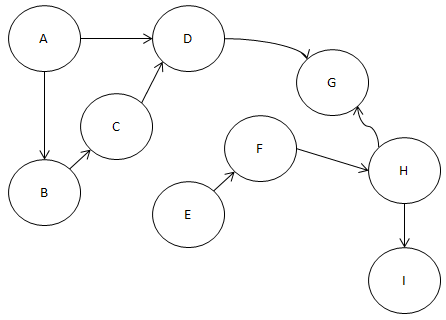
오늘은 위상 정렬에 대해서 하도록 하겠습니다.
이게 대체 무엇을 하는 알고리즘일까요?
음. 쉬운 예를 들어봅시다.
Rpg 게임 한 번 쯤 해봤다면
어떤 스킬을 배우는 데 필요한 조건이 있을 겁니다.
즉, 어떤 스킬과 전제가 되는 스킬은
서로 선후관계가 있는 것이죠?
자. 메이플 같은 경우에도
1차 Sp를 다 투자해야 2차 스킬을 배울 수 있어요.
이런 선행 관계도 있지요?
자. 이러한 관계를
차근 차근 정리해 주는 알고리즘이 위상 정렬입니다.
실생활에서도 이러한 예는 쉽게 찾아볼 수 있죠.
예를 들어서 어떤 과목을 배우기 위한 선수 과목.
이 둘의 관계 역시 선후 관계잖아요?
자. 위상 정렬은 순서를 정해주는 알고리즘입니다.
그러면 사이클이 있거나
방향성이 없다면
순서가 정해질 수 있을까요?
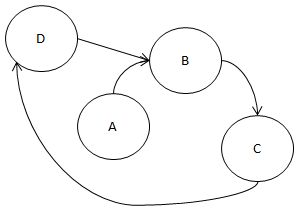
당연히 순서가 정해질 수 없을 겁니다.
B를 먼저 하고 C를 그 다음에 하고
그 다음에 D를 하고 다시 B를 하고..
이런 식으로 순서가 정해질 수 없죠.
즉, 그래프가 DAG여야 위상 정렬이 가능합니다.
이게 무슨 약자냐고요?
Directed Acycilc Graph
맞나 모르겠네. 방향이 있는 비순환 그래프.
자. 일단 코드를 먼저 보고
설명을 드리도록 하겠습니다.
ⓑ : 코드 보기

저 같은 경우 위상 정렬을 하기 위해
자료구조를 이렇게 정의했습니다.
Count는 들어오는 간선의 수고요.
Order는 순서 중 하나를 저장하기 위한 배열이고요.
사실 이것 외에는 별 것이 없어 보입니다.
일단 이 부분 뭔지는 모르겠는데
for문이 2번 돌아가는 걸로 봐서는
시간 복잡도가 O(MT) 정도 되겠네요.
그리고 이 부분을 봅시다.
진입 간선이 없는 노드를 선택하는 데
사실 이 알고리즘은 시간 복잡도가 O(N)
그 노드를 불러와서
진출 간선을 제거하는 데 O(N)
그리고 그것을 N번 수행하니까
사실 O(N^2)꼴로 정리가 되긴 합니다.
물론 N은 가수의 수니까
위상 정렬의 그래프로 따지면
노드의 수 정도 되겠지요.
일단 이 알고리즘에 대해서
먼저 설명해 드리도록 하죠.
코드가 길어 보여도
주석은 충분히 달아놨기 때문에
별로 어렵지 않을 겁니다.
그래도 이해 안 가시는 분들을 위해서
그림으로 자세히 설명해 드립니다.
ⓒ : 예제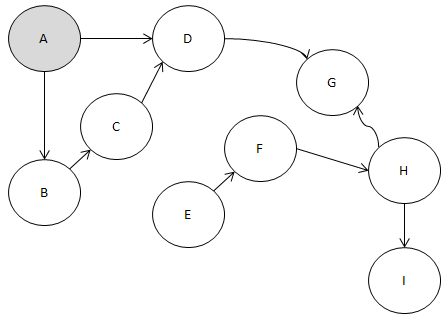
일단 우리는 다음과 같이 생각해 봅시다.
일단 진입 간선이 0개인 녀석을 찾습니다.
그리고 그 녀석을 찾으면
그 녀석에서 빠져 나가는 간선을 모두 제거합시다.
음. 예를 들어서
만약에 A라는 스킬을 찍어야 B를 찍을 수 있다는 관계가 있다면
일단 A라는 스킬을 가지고 있는 노드는
선행 조건이 없잖아요.
그리고 B라는 스킬은
A라는 스킬을 찍었다는 전제 하에서는
선행 조건이 또 없지요.
그런 이야기 입니다.
자. 일단 진입 간선의 수가 0인 노드 A를 봅시다.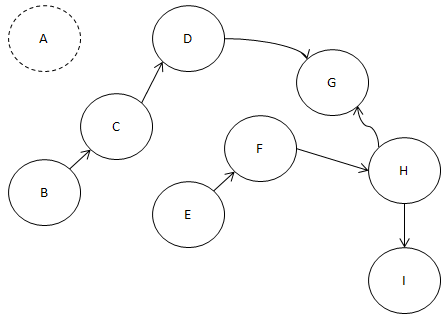
노드 A에서 나가는 진출 간선 2개를
제거하면 이렇게 되지요?
그리고 진입 간선이 0개인 노드를 찾읍시다.
B와 E가 남았죠?
알파벳 순으로 빠른 B를 뽑죠.
그러면 B에서 나가는 간선이 제거되겠군요.
다시. 이게 뭘 의미하느냐.
내가 B라는 스킬을 찍었다는 것을 의미해요.
일정한 레벨 이상으로.
B라는 스킬을 일정 레벨 이상 찍었을 때
C라는 스킬을 찍을 수 있다고 해 봐요.
만약 내가 B라는 스킬을 일정 레벨 이상 찍으면
C라는 스킬은 다른 조건 없이 찍을 수 있잖아요?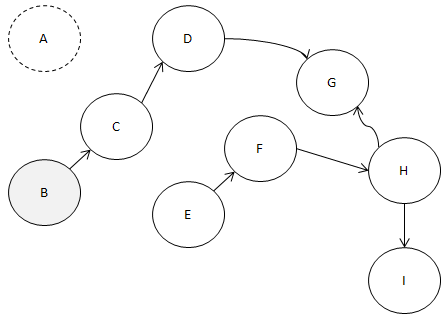
B를 선택해서 B에서 나가는 간선을
모두 제거하도록 합시다.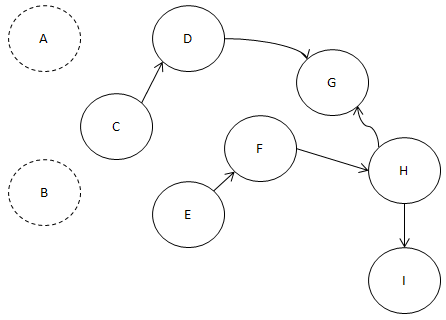
그러면 관계가 이렇게 나오는 군요.
이제 다시 한 번 볼까요?
C와 E가 아무런 조건 없이 수행될 수 있죠?
이 중 알파벳 순으로 빠른 노드를 찾으면 C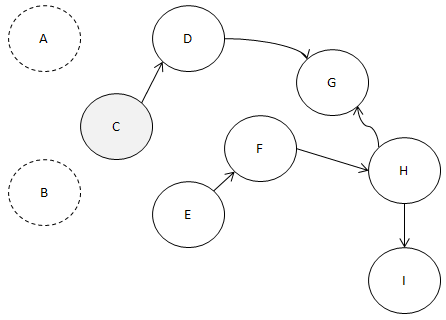
맞아요? 진입 간선 수가 0이니까요.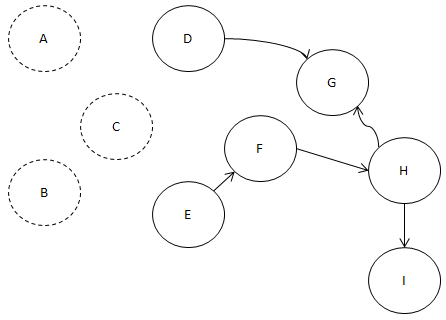
C에서 나가는 간선을 모두 제거하고
이제 남은 녀석들을 봅시다.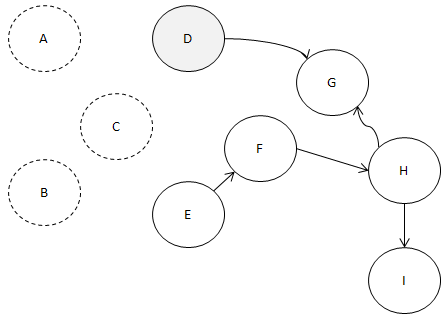
D와 E라는 녀석 말이죠.
진입 간선이 0개입니다.
맞죠? 이 중에서 알파벳 순으로 빠른
D를 먼저 빼 보지요.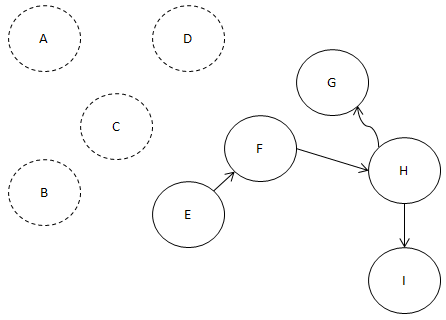
그러면 이렇게 되는군요.
D에서 나가는 간선도 제거했고요.
E로 진입하는 간선이 0개죠?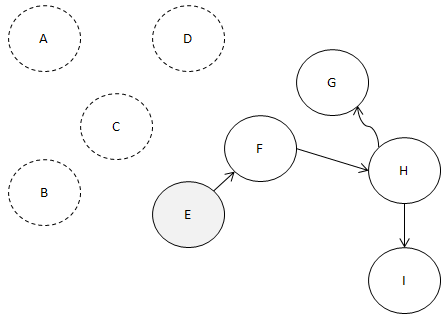
그렇죠? 맞지요?
따라서 E와 E에서 나가는 간선을 제거합니다.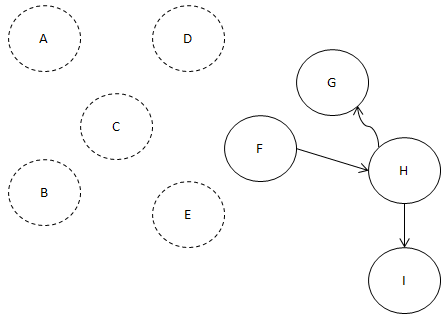
그러면 이렇게 남는군요. 냠냠.
자. F로 들어오는 간선이 1개도 없습니다.
나머지는 1개씩 있는 상태죠..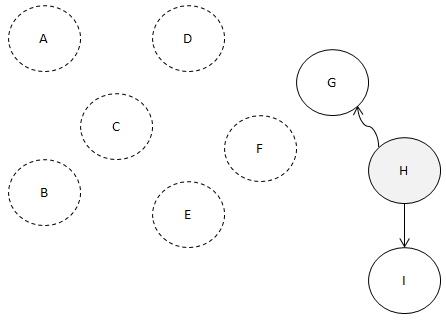
F를 출력해 주시고
이렇게 나왔네요.
F에서 나가는 간선도 제거했으니 말이죠.
H로 들어오는 간선이 없죠?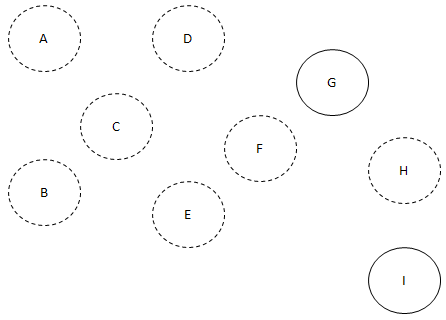
H와 H에서 나가는 간선을 제거해 줍시다.
그러면 G와 I 이렇게 2개가 남습니다.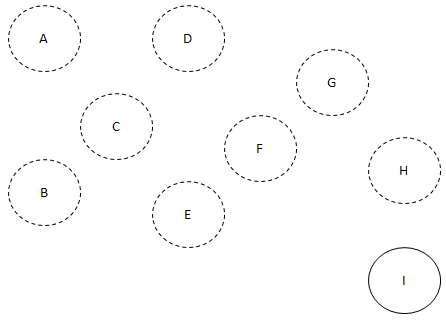
차례 차례 제거하도록 합시다.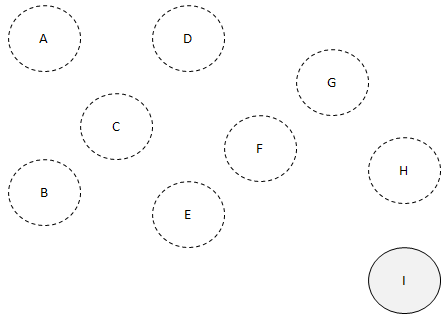
나머지 I도 얼른 제거합시다.
위상 정렬 결과입니다.
A B C D E F H G I
이 정도면 꽤 좋지요.
이해하기 쉽죠?
일단 들어오는 간선의 수가 0인 노드를 방문해서
그 노드의 진출 간선을 모두 제거하고
또 다시 들어오는 간선의 수가 0인 노드를 잡고.
만약 모든 노드를 방문하기 전에 끝났다면
이 그래프는 DAG가 아니라는 소리죠.
일단 이 처리는 해주시면 좋을 듯 하고요.
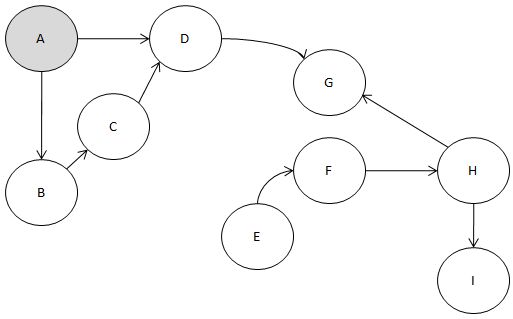
자. 이번엔 다른 방법으로 해 보죠.
DFS, 즉 깊이 우선 탐색 방법으로 해보겠습니다.
DFS면 딱 생각나는 게 있죠?
갈 수 없는 길을 만날 때 까지 가 본다.
일단 두 노드가 있을 때는
알파벳 순으로 탐방을 하도록 합시다.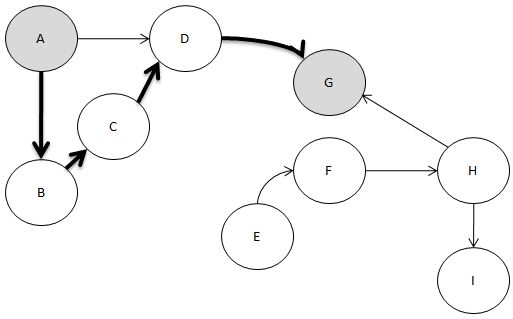
어휴. 자. 일단 진입 간선이
0인 노드를 찾는 데 걸리는 복잡도가 어느 정도 됩니까?
자. 들어오는 간선수를 저장해 뒀다면
단순히 O(V) 아니겠습니까?
이런 식으로 깊이 우선 탐색을 실시 합니다..
DFS 알고리즘은 제가 저번에 보여드린 듯 하고요.
여기서 하나 더 두어 볼까요?
일단.. 갈 수 없을 때 까지 DFS를 합니다.
그리고 여기서 주목해야 할 것은..
다시 백 트래킹 하는 것입니다.
다시 오다니. 그게 무슨 소리요?
자. 일단 여기까지 수행했을 때
이렇게 삽입이 되어 있을 겁니다.
A B C D G
맞아요?
이 과정을 하나 하나 보여드리겠습니다.
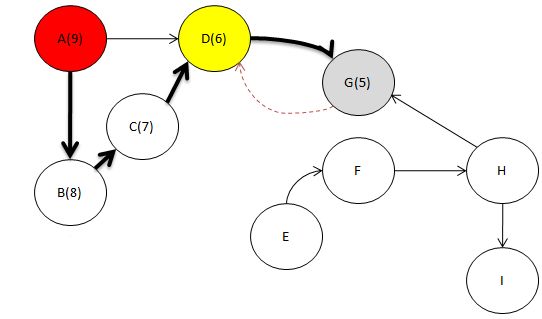
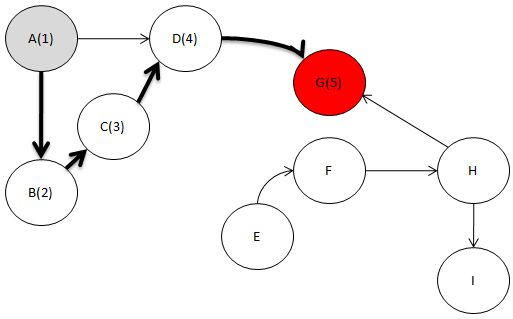
자. G로부터 거꾸로 올라가서
현재 D라는 녀석에 있다고 칩시다.
자. D와 인접하면서
깊이 우선 탐색으로 방문하지 않은 노드 있나요?
아니요. 없습니다.
따라서 D를 Head에 삽입을 해야 겠지요.
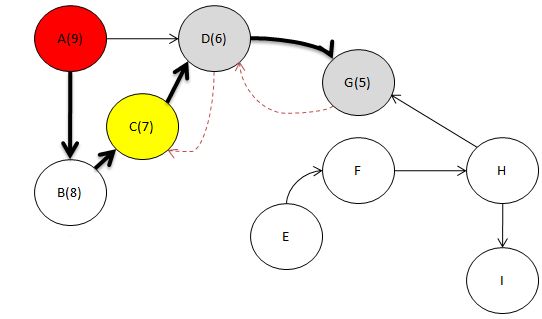
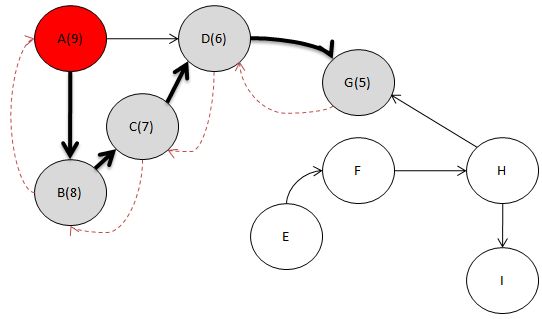
자. 이제 C를 봅시다.
역시 마찬가지입니다.
C와 인접하면서 DFS 탐색으로 방문하지 않은 노드 없죠?
따라서 C를 Head에 추가합니다.
이런 식으로 내가 먼저 깊이 우선 탐색을 한 것을
거꾸로 백 트래킹을 해 가면서
깊이 우선 탐색으로 방문하지 않았으면서
인접한 정점이 있다면
추가 작업을 해 줘야 겠지요.
자. 이제 또 다시 In 간선 수가 0인 노드를 찾죠.
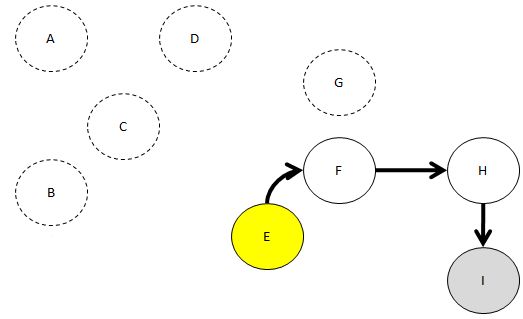
E로 들어오는 간선의 수가 0이군요.
자. 일단 DFS를 수행하면 다음과 같을 겁니다.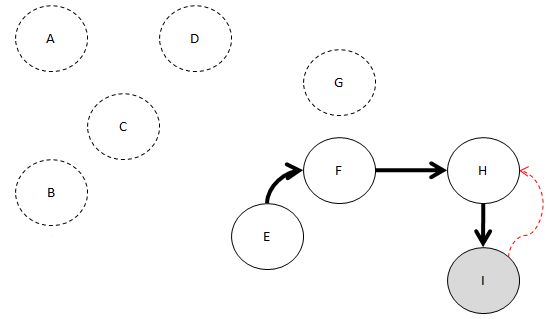
더 이상 갈 수 없는 길이 있네요.
I라는 녀석이 있죠?
여기서 부터 다시 백 트래킹 시작.
왔던 길을 다시 되돌아 가는 겁니다.
I 보세요. 더 이상 갈 수 없죠?
Head에 추가합니다.
일단 님들이 실행 시간을 숫자로 기록 해보시길.
규칙 찾으실 수 있습니다.
노드 H로 갑니다.
이미 I는 방문했는데..
H와 인접한 녀석 중에서 방문 안 한 녀석 없죠?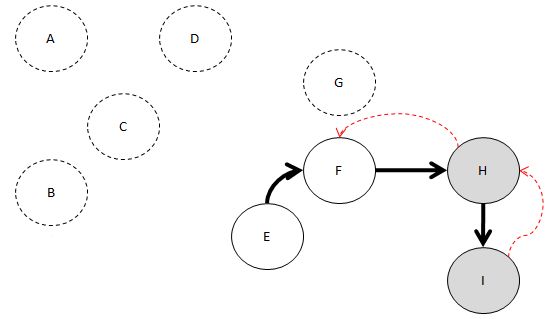
자. 이제 H를 Head에 넣고
다시 뒤로 갑시다.
F가 있군요. 그렇죠?
그런데 F 말이죠.
F와 인접하면서 방문하지 않은 노드 없죠?
그냥 F도 닥치고 Head에 추가합니다.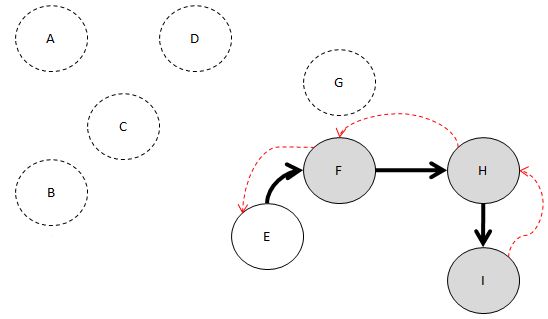
이제 E가 남았군요.
역시 마찬가지입니다.
E와 인접하면서 방문하지 않은 노드 없죠?
따라서 Head에 추가합니다.
만약에 이런 그래프였다면 어떨까요?
만약에 H의 인접 노드가 I가 아니라
I의 인접 노드가 H였다면 어떻게 되었을까요?
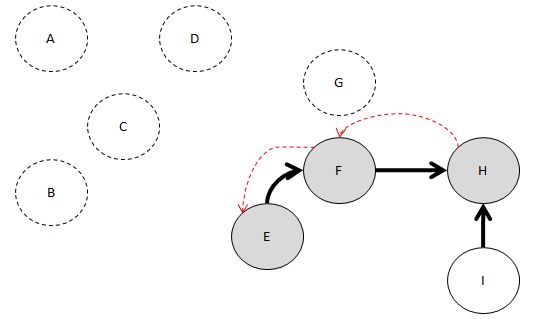
일단 이런 식으로 돌아오긴 할 겁니다.
그 다음에. I의 indegree 간선 수가 0이죠?
따라서 I를 Head에 추가하고 끝낼 겁니다.
사실 BFS로도 풀 거 같은데..
일단 DFS로 푸는 과정까지 보여드렸고요.
자. 이 것을 어떻게 링크드 리스트로 구현을 안 하고
배열로 구현을 해야 할 지 잘 생각해 보세요.
힌트는 실행 시간에 있습니다.
그것을 유심히 보시고요.
문제 하나 드리겠습니다.
ⓓ : 문제
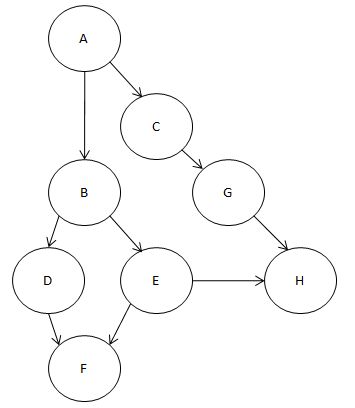
이 그래프를 DFS 방법으로 위상정렬 해 보세요.
물론 깊이 우선 탐색을 할 때
현재 내 위치로 부터 자식 노드가 2개 이상 있다면
알파벳 순으로 우선인 것을 먼저 잡으세요.
실행 과정을 그림으로 그리세요.
# :
덧글과 공감은
블로거에게 큰 힘이 됩니다
[출처] 위상 정렬 (Topological Sort)|작성자 조가희
'알고리즘' 카테고리의 다른 글
| 이진탐색트리 Binary Search Tree! (0) | 2013.08.03 |
|---|---|
| 바이너리서치 (0) | 2013.08.02 |
| quick sort (0) | 2013.08.01 |
| 버블정렬, 삽입정렬 (0) | 2013.07.31 |
| 꿈틀꿈틀 (0) | 2013.07.30 |





